An announcement of an important new initiative that will help catalyze data-driven wildlife conservation by harnessing the power of technology and science to unite millions of photos from camera trap projects around the world and reveal how wildlife is faring, in near real-time:
Wildlife Insights is combining field and sensor expertise, cutting edge technology and advanced analytics to enable people everywhere to share wildlife data and better manage wildlife populations. Anyone can upload their images to the Wildlife Insights platform so that species can be automatically identified using artificial intelligence. This will save thousands of hours, freeing up more time to analyze and apply insights to conservation.
By aggregating images from around the world, Wildlife Insights is providing access to the timely data we need to effectively monitor wildlife. We are creating a community where anyone can explore images from projects around the world and leverage data at scale to influence policy.
Wildlife Insights provides the tools and technology to connect wildlife “big data” to decision makers. This full circle solution can help advance data-driven conservation action to reach our ultimate goal: recovering global wildlife populations.
,
Read More » Posted in Cloud, Google, Open Source, Sensors | Comments Off on Wildlife Insights: Data-Driven Conservation Uniting Camera Trap Projects With Artificial Intelligence
Via Terra Daily, a look at the potential that sharing data has or improved forest protection and monitoring:
Although the mapping of aboveground biomass is now possible with satellite remote sensing, these maps still have to be calibrated and validated using on-site data gathered by researchers across the world. IIASA contributed to the establishment of a new global database to support Earth Observation and encourage investment in relevant field-based measurements and research.
Forest biomass is an essential indicator for monitoring the Earth’s ecosystems and climate. It also provides critical input to greenhouse gas accounting, estimation of carbon losses and forest degradation, assessment of renewable energy potential, and for developing climate change mitigation policies.
Although satellite remote sensing technology now allows researchers to produce extensive maps of aboveground biomass, these maps still require reliable, up-to-date, on-site data for calibration and validation.
Collecting data in the field by measuring trees and documenting species is, however, a very labor intensive, expensive, and time-consuming exercise and it would therefore make sense to bring together the many extant data sets to provide real added value for a number of applications. In terms of policy applications, doing so can also lead to improved biomass products and better monitoring of forest resources, which could in turn lead to more effective forest protection measures.
In a new paper published in the journal Scientific Data, 143 researchers involved in this type of data collection in the field, explored whether it was possible to build a network that openly shares their data on biomass for the benefit of different communities.
They particularly wanted to see if they could bring together as much on-site data on biomass as possible to prepare for new satellite missions, such as the European Space Agency’s BIOMASS mission, with a view to improving the accuracy of current remote sensing based products, and developing new synergies between remote sensing and ground-based ecosystem research communities.
Their efforts have resulted in the establishment of the Forest Observation System (FOS) – an international, collaborative initiative that aims to establish a global on-site forest aboveground biomass database to support Earth Observation and to encourage investment in relevant field-based measurements and research.
“Keeping in mind that this paper is a data descriptor and not a conventional paper with hypotheses, the whole idea behind this study is a new open database on biomass data. This is important for the following reasons: First, it represents a way to link the ecological/forestry and remote sensing communities.
It also overcomes existing data sharing barriers, while promoting data sharing beyond small, siloed communities. Lastly, it provides recognition to the people working in the field, including those who collect the data, which is why there are 143 coauthors on this paper, as they are all contributors to the database,” explains study lead author Dmitry Shchepashchenko, a researcher in the IIASA Ecosystems Services and Management Program.
The researchers collected data from 1,645 permanent forest sample plots from 274 locations distributed around the globe. This data has now been made available for download via the FOS website. The initiative represents the first attempt at bringing this type of data together from different networks in a single location.
The researchers point out that their work in this regard is ongoing and there are plans to continue adding more data sets and networks to the FOS. In addition to promoting data sharing, the system also promotes a new leading network on biomass data (through the FOS), which IIASA is leading and will continue to grow into the future.
Apart from the obvious benefits that data sharing hold for the scientific community, the data are also essential for training various models at IIASA such as the BioGeoChemistry Management Model (BGC-MAN) and the Global Forest Model (G4M). Several on-going IIASA projects, as well as other ecological-, biophysical-, and economic models and projects outside of IIASA will also benefit, which means that providing access to the data can improve models and understanding of biomass more generally.
“A great deal of effort has gone into collecting forest data in the past, but people working in the field (ecologists and forestry scientists) hardly ever share the collected data, or if they do, they share it only within ecological networks. The data are valuable not only for ecology, but also for remote sensing calibration and validation, in other words, to train algorithms that create biomass maps, and for assessing the accuracy of the products along with inputs to a variety of models. This piece of work represents a real step forward in sharing a very valuable biomass data set,” concludes IIASA researcher Linda See, who was also a study coauthor.
,
Read More » Posted in Satellite | Comments Off on Sharing Data For Improved Forest Protection And Monitoring
Via the Harvard Business School, a look at how the gap between technology and science is bridged by machine learning and artificial intelligence:
A decade on from the financial crisis that saw stock markets crash, oil prices collapse, and clean technology venture funding dwindle, we’re seeing signs that “cleantech” and sustainability-focused technologies are back in focus — with the effects of climate change ever more apparent and increasingly urgent. As noted in a recent podcast by The Interchange from Greentech Media, this renewed interest comes from a variety of players ranging from startup entrepreneurs to established companies and new venture funds.
While climate change is portrayed as a divisive political issue, the scientific evidence is hard to ignore and extends across a range of quantifiable metrics including: the number of extreme weather events, rate of sea level rise, extent of coral reef damage linked to ocean acidification, and warming of ocean temperatures. Climate change is the reality that individuals and companies are navigating and have to account for.
The complexity of the climate crisis is often exacerbated by the sheer volume of data, which makes manual analysis intractable. Machine learning and artificial intelligence (AI) have made waves in many software technologies because of their ability to analyze and draw inferences from large amounts of granular data. Researchers, entrepreneurs, and businesses have responded to the immediacy of climate change by combining domain expertise, various data sources, and machine learning and AI to not only better understand the science behind climate change, but also innovate across a variety of sectors including energy, food and agriculture, transportation, and infrastructure.
Algorithms, such as convolutional neural networks originally designed for classifying images, allow researchers and companies to analyze high resolution satellite imagery provided by government agencies and private companies. This spatio-temporal information can provide insights on poverty, vegetation and land cover changes, and even infrastructure quality. When monitored over time, the sequences of these satellite images and the algorithmically extracted insights paint a picture of how climate change has impacted society.
In the energy sector, several startups have gained attention and investments from corporate venture funds like Shell Ventures and National Grid Partners, as well as seed accelerators like Y Combinator and even the billionaire-backed Breakthrough Energy Ventures (BEV):
Autogrid – Machine learning and analytics to help utilities, electricity retailers, and renewable energy developers flexibly extract capacity from distributed energy resources (Shell Ventures, National Grid Partners)
Traverse Technologies – AI-driven prospecting for optimal hydropower and wind generation sites (Y Combinator)
KoBold Metals – Computer vision and machine learning-enabled digital prospecting to search for likely sources of cobalt (BEV, Andreessen Horowitz)
Technology companies have also applied their AI research to help address climate change — first internally and increasingly for external use. Google DeepMind, known for defeating a Go world champion with their program AlphaGo, first applied their technology to reduce Google’s data center cooling energy usage in 2016. The team was able to reduce energy usage by 40% through applying machine learning programs to help improve operational efficiency. Additionally, DeepMind has applied deep learning to improve renewable energy generation by forecasting wind energy generation in order to provide more reliable estimates of when power would actually be generated. This helped boost the value of the wind energy generation by 20% and inform the hourly commitments that were promised to the power grid.
Meanwhile, Microsoft has applied machine learning research to its services and calculated, in a recent study, that its cloud services are up to 93% more energy efficient and up to 98% more carbon efficient than traditional enterprise data centers. Externally, Microsoft has pledged $50 million over 5 years to support organizations and researchers looking to tackle environmental challenges through their AI for Earth program.
While deep learning has helped startups and technology companies tackle climate problems, it needs to be balanced with a critical look at the resources used in model training. Researchers at the University of Massachusetts, Amherst have recently found that training large AI systems, given the existing mix of energy sources, emits large amounts of carbon dioxide. These results illustrate the importance of relying on renewable energy sources to fuel the development of these machine learning technologies.
As climate change’s effects continue to necessitate immediate action, companies have started to turn to machine learning and AI to help navigate vast amounts of complex data to help improve decision making. In many cases, the combination of better technology in improved algorithms and better data have allowed businesses to not only reduce their impact on the environment but also operate more efficiently. While the magnitude of climate change requires a variety of technologies and solutions, machine learning and AI are powerful new tools in the fight against climate change. The confluence of these technologies with the explosion of large quantities of accessible data presents a critical new opportunity for humanity to pave a more sustainable path forward.
,
Read More » Posted in Blog | Comments Off on Climate Intelligence
Via Harvard Business School, an interesting article on the use of satellites to map the most at-risk agricultural zones to devise plans for safeguarding crops:
Around the world, farmers are wrestling with floods, droughts, and heat waves — environmental challenges to agriculture that are made both more severe and more frequent by climate change. In the US, this year’s record flooding in the Midwest and Great Plains caused over $3 billion in damage and left many farmers unable to plant, and vulnerable to subsequent heat waves. Rates of warming in Kenya already exceed the 1.5° threshold targeted by the Paris Agreement, with dire consequences for livestock and other forms of agriculture.
Imagine if we could predict how climate change will transform agriculture in the coming years, evaluating which crops are most vulnerable, and where. By identifying agricultural “hotspots” most exposed to climate change, we could begin to design adaptation strategies, including introducing more resilient crop species and, where possible, moving current crop cultivation to more accommodating ecologies. To do so, we would need a rigorous understanding of how environmental conditions affect crop yield, as well as detailed forecasts of how temperature and rainfall are likely to change in the years to come as climate change becomes more pronounced.
Building an accurate, working map of agricultural vulnerabilities due to climate change is the goal of Angela Rigden, a hydrologist and Rockefeller Foundation Planetary Health Postdoctoral Fellow at the Harvard University Center for the Environment. The first step in building such a map is improving current crop forecast models, which have traditionally used rainfall and temperature data to estimate “water stress” and “heat stress.” But, Rigden says, these are poor proxies for actual crop physiology. Just as sweating cools down our skin on a hot day, plants evaporate water from pores on their leaves in a process called “transpiration.” The amount of water lost to transpiration depends on the amount of water available in the root zone and the dryness of the air. Transpiration is often a good indicator of yield — the more a plant transpires, the more it yields.
Until recently, measuring soil moisture was difficult, so previous studies used rainfall as a proxy for root-zone soil moisture. But rainfall is not a great proxy for soil moisture because different conditions lead to big differences in rainfall runoff, drainage, and evaporation.
Earlier this spring at the Harvard Global Health Institute, Rigden described how she set out to build a better forecasting model. Rigden turned to a new source of data — a satellite launched by NASA in 2015 called SMAP (Soil Moisture Active Passive). SMAP measures the amount of water in the top two inches of soil everywhere on the Earth’s surface every three days, generating data on root-zone soil moisture that is free and publicly available. SMAP data allowed Rigden to build a significantly improved predictive model of corn yields by climatic conditions in the midwestern US.
Rigden then set out to complete a similar study in Africa, where agriculture is much more vulnerable to drought and other climatic influences. To do so, Rigden needed data on African agricultural yields, but the publicly available data on agricultural output was primarily at the country level — not fine-grained enough to assess the impact of local climate conditions. Instead, Rigden used data from a second, European satellite-based instrument known as GOME-2 (Global Ozone Monitoring Experiment-2) that could detect fluorescence associated with photosynthesis. Rigden and her coauthors demonstrated that this fluorescence is a remarkably effective proxy for crop yield that allowed Rigden to describe the likely impact of varying climate conditions.
Mapping her model of crop yields against forecasts of climate change, Rigden is able to show that, although cultivation of corn in the midwestern US is relatively secure under most climate scenarios due to adequate availability of moisture, tea cultivation in Kenya is much more vulnerable, facing a decline of around 11% — a significant challenge, given the significance of tea in Kenya’s economy, which exports over $1 billion dollars annually. Rigden’s research suggests that this decline might be mitigated by, for example, planting drought-resistant tea cultivars and moving tea cultivation to higher altitudes. Such changes involve a long-term commitment, though, because tea plants require at least three years of maturation before harvest and have an economic lifespan of 50-60 years.
Climate change poses a grave threat to food security and global health. Ensuring that we can continue to feed the world’s growing population despite climate change will require effective adaptation measures by both governments and private agribusiness — what the United Nations’ Food and Agriculture Organization calls “Climate-Smart Agriculture.” Rigden’s case studies of Kenya and the American Midwest represent first steps in making our forecasts of the impacts of climate change on agriculture in different parts of the world accurate enough to guide adaptation strategies to safeguard the world’s ability to feed itself.
Anglea Rigden is currently performing a third case study in Madagascar. Collaborating with researchers in Harvard’s School of Public Health, she aims to utilize the crop predictions in conjunction with expert knowledge of local social, political, and economic events to predict and alleviate food insecurity in this region.
,
Read More » Posted in Satellite | Comments Off on Forecasting Agricultural Vulnerabilities On A Changing Planet
Via World Economic Forum, a look at how data and technology can help tackle the globe’s water pollution challenge:
Humans have wrestled with water quality for thousands of years, as far back as the 4th and 5th centuries BC when Hippocrates, the father of modern medicine, linked impure water to disease and invented one of the earliest water filters. Today, the challenge is sizeable, creating existential threats to biodiversity and multiple human communities, as well as threatening economic progress and sustainability of human lives.
Increasing the economic and human cost of toxic water-bodies
To set up effective interventions to clean rivers, decision-makers must be provided with reliable, representative and comprehensive data collected at high frequency in a disaggregated manner. The traditional approach to water quality monitoring is slow, tedious, expensive and prone to human error; it only allows for the testing of a limited number of samples owing to a lack of infrastructure and resources. Data is often only available in tabular formats with little or no metadata to support it. As such, data quality and integrity are low.
Using automated, geotagged, time-stamped, real-time sensors to gather data in a non-stationary manner, researchers in our team at the Tata Centre for Development at UChicago have been able to pinpoint pollution hotspots in rivers and identify the spread of pollution locally. Such high-resolution mapping of river water quality over space and time is gaining traction as a tool to support regulatory compliance decision-making, as an early warning indicator for ecological degradation, and as a reliable system to assess the efficacy of sanitation interventions. Creating data visualizations to ease understanding and making data available through an open-access digital platform has built trust among all stakeholders.
Pictorial representation of a non-stationary, real-time sensor system with cloud-based data storage and digital dissemination capabilities
How machine learning can produce insights
Beyond collecting and representing data in easy formats, there is a possibility to use machine learning models on such high-resolution data to predict water quality. There are no real-time sensors available for certain crucial parameters estimating the organic content in the water, such as biochemical oxygen demand (BOD), and it can take up to five days to get results for these in a laboratory. These parameters can potentially be predicted in real-time from others whose values are available instantaneously. Once fully developed and validated, such machine learning models could predict values for intermediary values in time and space.
Real-time application of a neural network to easily available parameters to predict other water quality indicators
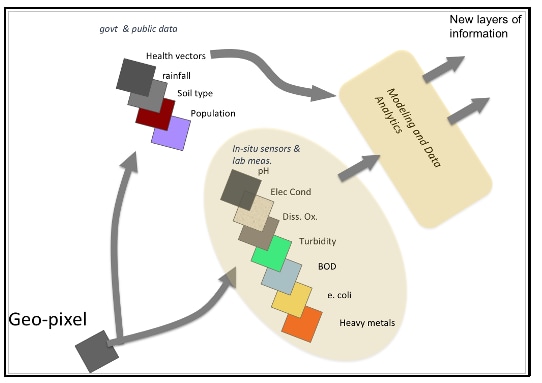
Furthermore, adding other layers of data, such as the rainfall pattern, local temperatures, industries situated nearby and agricultural land details, could enrich the statistical analysis of the dataset. The new, imaginary geopixel, as Professor Supratik Guha from the Pritzker School of Molecular Engineering calls it, has vertical layers of information for each GPS (global positioning system) location. Together they can provide a holistic picture of water quality in that location and changing trends.
The new imaginary geopixel, as Professor Supratik Guha from the Pritzker School of Molecular Engineering calls it, has vertical layers of information for each geotagged location
Technology and public policy
In broad terms, machine learning can help policy-makers with estimation and prediction problems. Traditionally, water pollution measurement has always been about estimation – through sample collection and lab tests. With our technology, we are increasing the scope and frequency of such estimation enormously – but we are also going further. With our machine learning models, we are trying to build predictive models that would completely change the scenario of water pollution data. Moreover, our expanded estimation and prediction machine learning tools will not just deliver new data and methods but may allow us to focus on new questions and policy problems. At a macro level, we aim to go beyond this project and hope to bring a culture of machine learning into Indian Public Policy.
Data disclosure and public policy
Access to information has been an important part of the environmental debate since the beginning of the climate change movement. The notion that “information increases the effectiveness of participation” has been widely accepted in economics and other social science literature. While the availability of reliable data is the most important step towards efficient regulation, making the process transparent and disclosing data to the public brings many additional advantages. Such disclosure creates competition among industries on environmental performance. It can also lead to public pressure from civil society groups, as well as the general public, investors and peer industrial plants, and nudge polluters towards better behaviour.
,
Read More » Posted in Satellite, Water | Comments Off on How Technology and Reliable Data Can Help Tackle Water Pollution
New technical innovations such as location-tracking devices, GPS and satellite communications, remote sensors, laser-imaging technologies, light detection and ranging” (LIDAR) sensing, high-resolution satellite imagery, digital mapping, advanced statistical analytical software and even biotechnology and synthetic biology are revolutionizing conservation in two key ways: first, by revealing the state of our world in unprecedented detail; and, second, by making available more data to more people in more places. The mission of this blog is to track these technical innovations that may give conservation the chance – for the first time – to keep up with, and even get ahead of, the planet’s most intractable environmental challenges. It will also examine the unintended consequences and moral hazards that the use of these new tools may cause.Read More